因果推断工具包详解
GIS空间数据分析的新视角
从理论到实践:主流因果推断框架在地理信息系统中的应用

课程目录
第一部分
引言与理论基础
因果推断核心概念、GIS应用场景、空间数据特点
第二部分
因果图与贝叶斯网络
DoWhy、CausalNex框架详解
第三部分
机器学习因果推断
EconML、CausalML方法
第四部分
空间计量经济学
PySAL、MGWR模型
第五部分
时间序列与贝叶斯
Tigramite、PyMC框架
第六部分
总结与展望
方法对比、未来方向
因果推断概述
什么是因果推断
- 研究变量之间的因果关系
- 回答"如果改变X,Y会如何变化"
- 涉及反事实推断
- GIS应用:城市扩张对环境的影响
为什么GIS需要因果推断
- 传统GIS分析关注空间格局
- 难以回答政策干预效果问题
- 需要评估真实效果
- 理解空间溢出效应
核心挑战
- 反事实推断:无法直接观察
- 混杂因素:同时影响原因和结果
- 选择性偏差:非随机样本
- 空间自相关和异质性
因果推断的核心概念
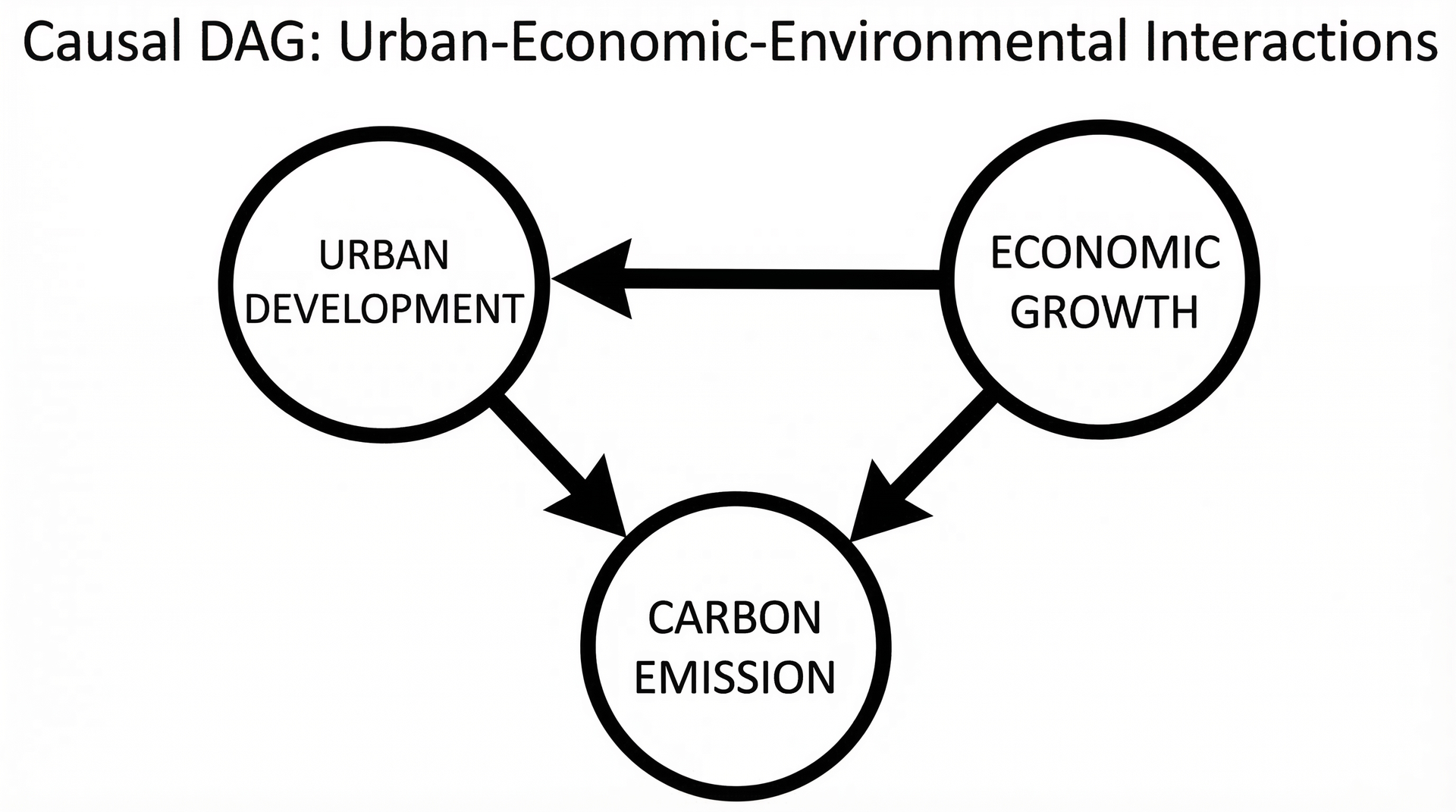
因果图模型(DAG)
节点表示变量,有向边表示因果关系。利用图论方法识别因果效应。
潜在结果框架
每个个体有Y(1)和Y(0)两个潜在结果。因果效应:Y(1)-Y(0)。
do算子
do(X=x)表示强制设置X为x,与条件概率P(Y|X)不同。
因果推断与统计相关性的区别
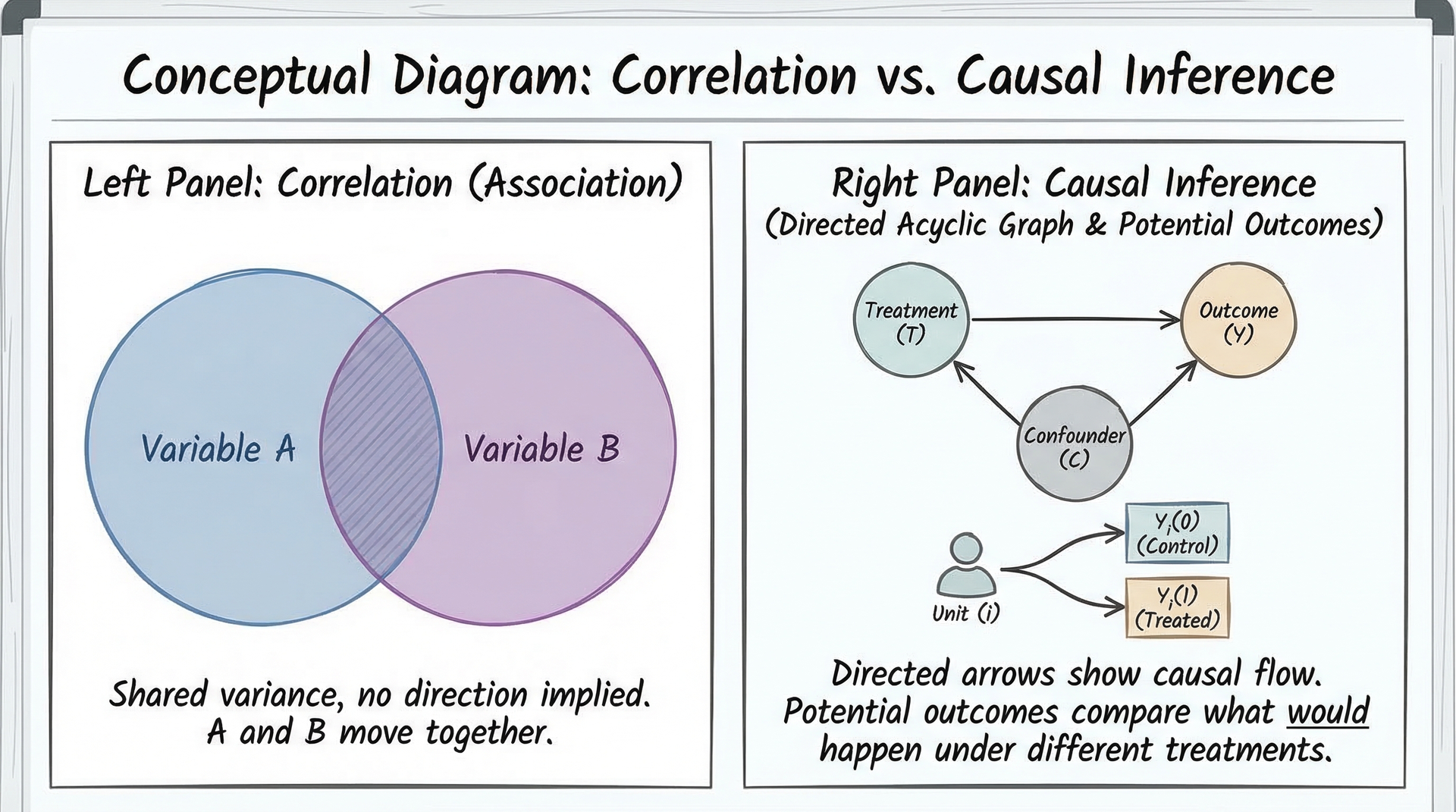
关键区别
- 相关性:描述数值关联
- 因果性:说明影响方向
- 辛普森悖论:分层分析中的逆转
- 需要控制混杂因素
GIS案例
公园与房价正相关,但实际由收入混杂。使用工具变量识别真实因果效应。
GIS中的因果推断应用场景
城市规划与土地政策
- 城市扩张边界控制效果
- 地铁线路对房价影响
- 新城建设对区域经济带动
- 控制郊区发展政策评估
交通基础设施分析
- 高速公路网络经济一体化
- 机场迁建对产业布局影响
- 物流枢纽区域产业集聚
- 交通网络空间溢出效应
环境与公共健康
- 绿地覆盖对健康影响
- 空气污染治理政策效果
- 水体质量变化归因
- 环境正义空间分析
空间数据的特点与因果推断挑战
空间自相关问题
相邻区域的空间变量具有相似性,违反独立性假设。
- 导致标准误差低估
- 影响统计推断
- 需要空间计量模型
空间异质性问题
地理现象在不同位置具有不同行为特征。
- 相同政策不同效果
- 因果机制随尺度变化
- 需要局部模型
空间溢出效应与空间异质性
空间溢出效应
- 直接效应:本区域政策影响本区域结果
- 间接效应:政策扩散到邻近区域
- 前向/后向溢出

空间异质性形式
- 空间自相关:相邻依赖关系
- 非平稳性:回归系数随位置变化
- 区域差异:不同子区域参数不同
工具变量与空间工具变量
工具变量的基本原理
工具变量Z需要满足:
- 相关性:Z与处理变量X相关
- 排他性:Z只通过X影响Y
两阶段最小二乘法(2SLS):
- 第一阶段:用Z预测X
- 第二阶段:用预测的X估计Y
空间工具变量构建
- 空间滞后处理变量(WX)
- 利用空间权重矩阵
- 空间距离、自然地理屏障
- 行政边界作为工具
GIS应用案例
高铁对经济影响:使用"是否在高铁规划沿线"作为工具变量(基于历史规划和地理因素)。
第一部分小结
核心要点
- 因果推断回答"如果...会怎样"的反事实问题
- 因果图和潜在结果框架是理论基础
- GIS中需处理空间自相关、空间异质性
- 工具变量是处理内生性的重要方法
下一步学习
- DoWhy因果图框架
- CausalNex贝叶斯网络
- 因果假设的形式化与检验
- 实际GIS案例应用
第二部分
因果图与贝叶斯网络方法
DoWhy框架概述
DoWhy定位与特点
微软开源因果推理框架,基于因果图模型和do算子理论。
- 因果图建模(Causal Model)
- 因果效应识别(Identification)
- 因果效应估计(Estimation)
- 因果效应反驳(Refutation)
理论基础
DoWhy建立在两个理论基础上:Judea Pearl的因果图模型(do-calculus和后门准则)和Donald Rubin的潜在结果框架,统一了两个经典因果推断范式。
DoWhy核心概念:因果图与识别
因果图的构建原则
因果图需要明确声明因果假设:
- 节点:代表变量
- 有向边:代表直接因果关系
- 混杂因素:同时影响原因和结果
- 中介变量:因果传导路径
- 工具变量:只影响处理变量
因果效应识别准则
后门准则:
如果Z阻断X和Y之间的所有后门路径,则因果效应可识别。
前门准则:
即使存在未观测混杂,如果通过前门路径传导,也可以识别。
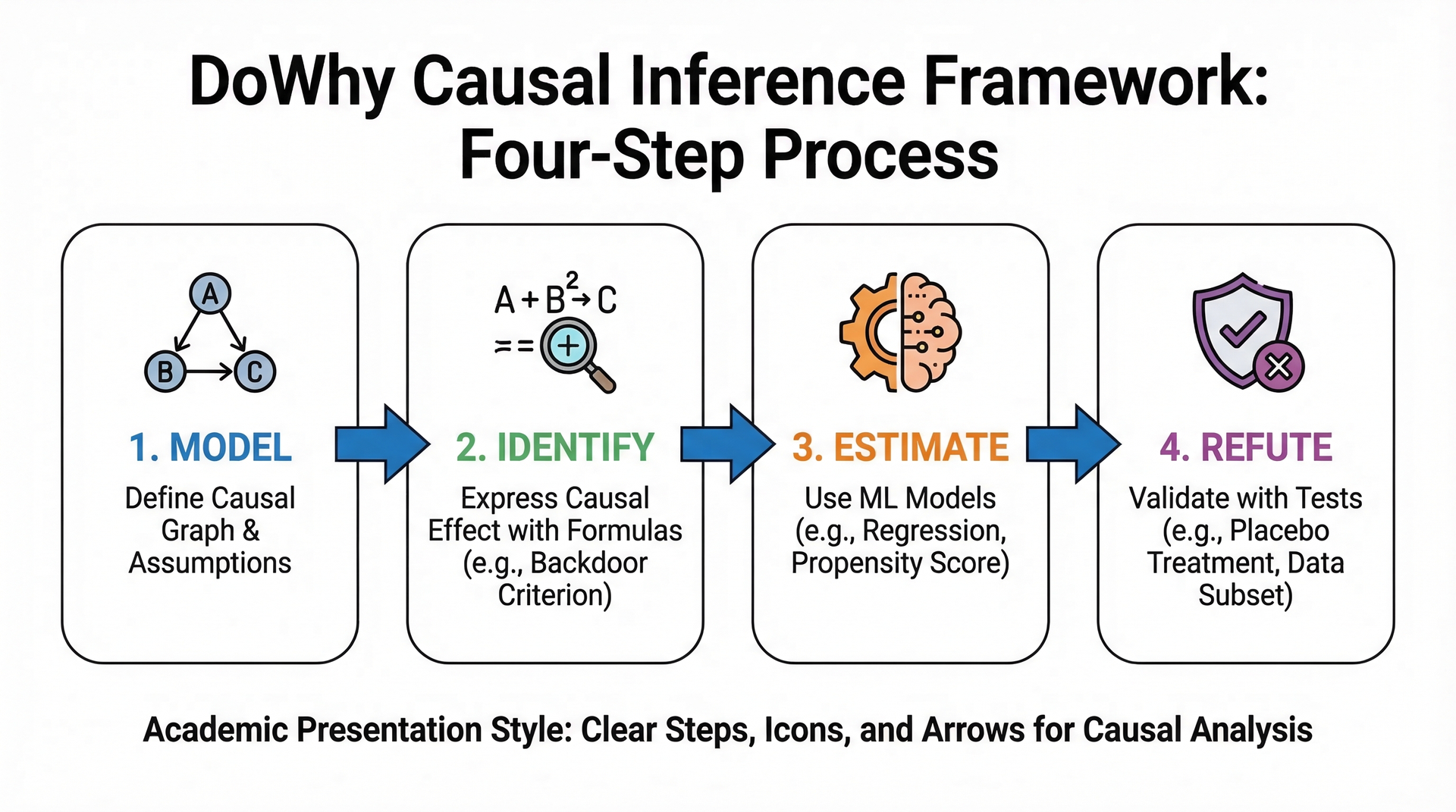
DoWhy四大步骤
1. 建模 (Model)
定义因果假设
声明混杂因素
构建因果图
2. 识别 (Identify)
验证效应可识别性
返回识别公式
后门调整公式
3. 估计 (Estimate)
从数据计算效应
多种估计方法
置信区间
4. 反驳 (Refute)
稳健性检验
添加混杂测试
伪处理测试
建模方式
- GML/dot语言描述
- 结构方程模型(SEM)
- 明确声明混杂因素
估计方法
- 倾向得分匹配
- 回归调整
- 工具变量
- 分层估计
反驳测试
- Random Common Cause
- Placebo Treatment
- Subset Validation
- Bootstrap
DoWhy案例:城市扩张对碳排放的影响
研究背景
研究问题:城市扩张是否导致碳排放增加?
- 土地从农业/林地转为城市用地
- 为城市规划政策提供科学依据
数据:
- 中国2000-2020年286个地级市
- 城市扩张指数、碳排放量
- GDP、人口、工业结构
因果图构建
包含:处理变量(城市扩张)、结果变量(碳排放)、混杂因素(GDP、人口、工业化)、中介变量(绿化覆盖、交通密度)
分析结果
每增加1%的城市用地比例,碳排放增加约0.8%。反驳测试验证了结果的稳健性。政策含义:控制城市扩张速度、优化城市空间布局可有效减少碳排放。
DoWhy代码示例
因果图定义
from dowhy import CausalModel
# 定义因果图
causal_graph = """
digraph {
urban_expansion -> carbon_emission;
urban_expansion -> green_coverage;
green_coverage -> carbon_emission;
GDP -> urban_expansion;
GDP -> carbon_emission;
population -> urban_expansion;
population -> carbon_emission;
industry -> urban_expansion;
industry -> carbon_emission;
}
"""
# 创建因果模型
model = CausalModel(
data=df,
treatment='urban_expansion',
outcome='carbon_emission',
common_causes=['GDP', 'population', 'industry'],
graph=causal_graph
)因果效应估计
# 识别因果效应
identified_estimand = model.identify_effect()
# 使用倾向得分匹配估计
estimate = model.estimate_effect(
identified_estimand,
method_name="backdoor.propensity_score_matching"
)
print(f"ATE估计值: {estimate.value}")
# 反驳测试
refutation = model.refute_estimate(
identified_estimand, estimate,
method_name="random_common_cause"
)
print(f"反驳测试p值: {refutation.p_value}")结果解读
ATE表示平均因果效应。置信区间反映不确定性。反驳测试帮助判断假设合理性。
CausalNex框架概述
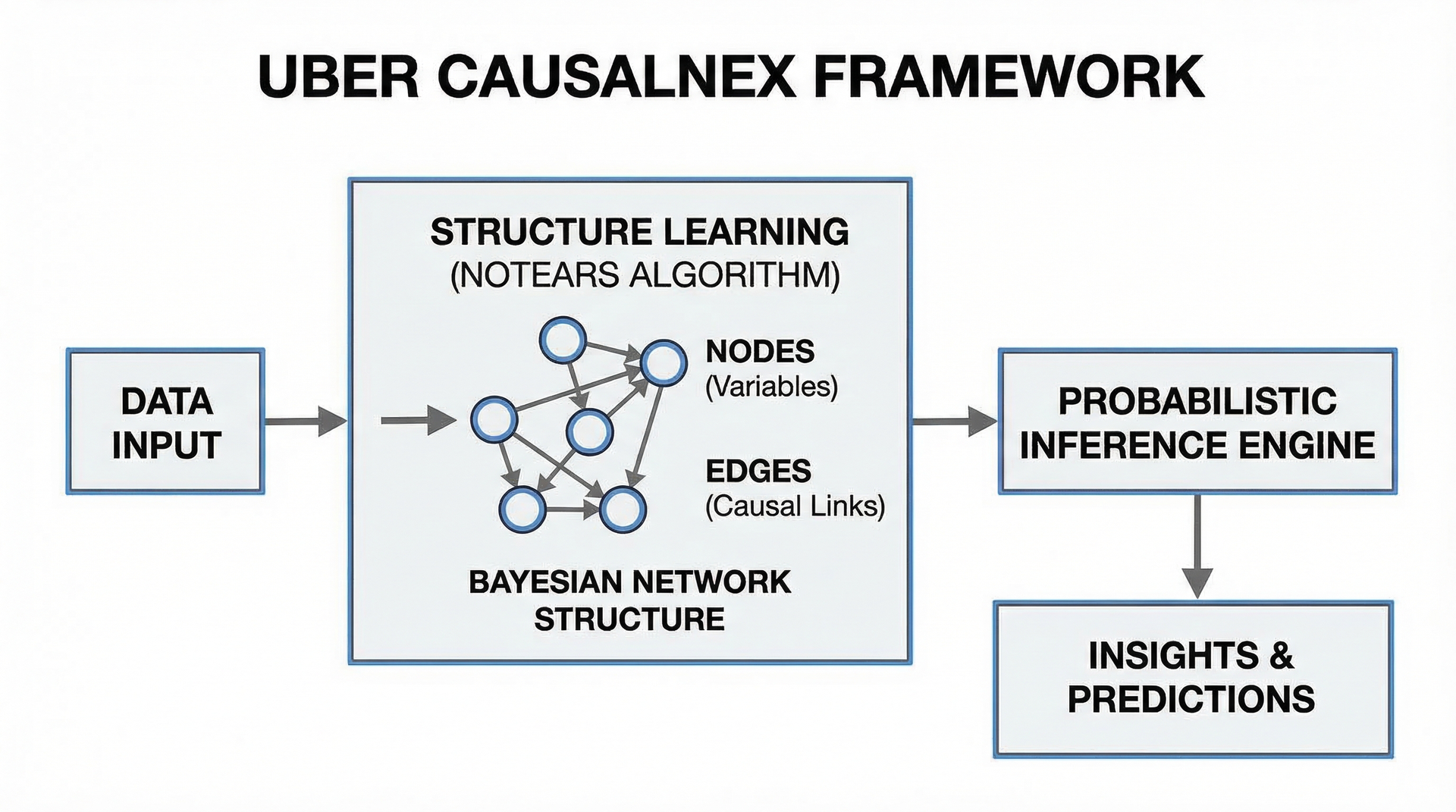
CausalNex定位与特点
Uber开发的因果推理库,专门用于从数据中学习因果结构并支持贝叶斯网络推理。
- 因果结构学习(NOTEARS算法)
- 因果效应估计
- 干预分析(what-if分析)
- 支持混合数据类型
理论基础
- 结构因果模型(SCM):有向无环图 + 结构方程
- 贝叶斯网络:概率推断能力
- 支持不确定性决策分析
核心优势
- 自动因果结构学习
- NOTEARS连续优化
- 与PyTorch深度学习结合
- 可视化工具
CausalNex因果结构学习
NOTEARS算法原理
Non-combinatorial Optimization via Trace Exponential and Augmented lagRangian for Structure learning
- 将离散图结构学习转化为连续优化
- 通过最小化观测数据与假设结构的不一致性
- 避免穷举所有可能的图结构
- 效率高,适合中等规模数据
CausalNex中的结构学习
from causalnex.structure import StructureModel
from causalnex.structure.notears import from_pandas
# 使用NOTEARS算法学习因果结构
sm = from_pandas(df, tabu_edges=None, w_threshold=0.3)
# 可视化
sm.plot()
# 核心参数
# type_forest: 节点类型
# tabu_edge_num: 禁止边数
# max_iter: 最大迭代次数GIS应用
从城市空间数据中学习因果结构,例如从交通、土地、经济数据中自动发现"交通密度→土地价格→商业集聚"等因果链条。
CausalNex贝叶斯网络推断
概率推断能力
给定贝叶斯网络,可以计算:
- 边缘概率:某个变量的分布
- 条件概率:给定其他变量条件下的分布
- 后验概率:观察到证据后的信念更新
干预分析(Do-calculus)
# 干预分析:强制设置交通密度为高
ie_intervention = InferenceEngine(bn)
ie_intervention.do_intervention(
'traffic_density', {'high': 1.0}
)
result_intervention = ie_intervention.query()
print(result_intervention['urban_growth'])应用场景
- 政策效果预测
- 资源优化配置
- 不确定性决策
- 反事实分析
CausalNex案例:交通网络与城市发展
研究问题
研究交通网络发展如何影响城市经济发展模式。
- 高速公路网络密度是否是城市经济增长的因果驱动因素?
- 是否存在时间滞后效应?
- 不同类型城市是否有不同响应?
数据与方法
- 中国2000-2020年城市面板数据
- GDP、第二/三产业比重
- 公路密度、铁路密度
- 人口规模、距主要城市距离
使用CausalNex NOTEARS学习变量间的因果结构。
研究发现
因果结构学习揭示了"交通网络→要素集聚→产业升级→经济增长"的传导链条。高速公路密度对GDP有显著正向因果效应,效应强度随距主要城市距离递减。结果支持了交通基础设施促进区域经济发展的理论假说。
CausalNex代码示例
结构学习代码
from causalnex.structure import StructureModel
from causalnex.structure.notears import from_pandas
# 使用NOTEARS算法学习因果结构
sm = from_pandas(df, tabu_edges=None, w_threshold=0.3)
# 可视化
sm.plot()
# 阈值过滤,去除弱因果边
sm.remove_edges_below_threshold(0.5)贝叶斯网络推断
from causalnex.inference import InferenceEngine
# 构建贝叶斯网络
bn = BayesianLNetwork(sm)
bn = bn.fit_node_states(df)
bn = bn.fit_cpds(df)
# 概率推断
ie = InferenceEngine(bn)
# 查询:给定交通密度高
result = ie.query({'traffic_density': 'high'})
print(result['urban_growth'])因果图方法的GIS应用总结
DoWhy vs CausalNex 对比
- DoWhy:给定假设下的效应估计,强调假设形式化和检验
- CausalNex:从数据中发现因果结构,支持概率推断
共同GIS应用模式
- 城市规划政策效果评估
- 环境影响的因果归因
- 空间溢出效应分析
选择DoWhy当
- 已有明确因果假设
- 需要严格的效应估计
- 需要反驳测试验证
选择CausalNex当
- 因果假设不明确
- 需要从数据中发现结构
- 需要贝叶斯概率推断
因果图构建的最佳实践
明确因果假设
- 结合领域知识
- 考虑地理因素(地形、气候、区位)
- 明确政策传导机制
- 识别可能的混杂因素
避免常见错误
- 遗漏重要混杂因素
- 错误声明因果方向
- 过度复杂化
- 遵循简约原则
敏感性分析
- 尝试不同因果图结构
- 检验结论是否稳健
- 使用反驳测试评估
- 比较不同学习参数
空间因果图模型
空间扩展的因果图
标准因果图不包含空间关系,但GIS应用需要考虑空间依赖性。
- 增加空间滞后变量Wx
- 相邻区域的X值作为变量
- 允许作为混杂或中介
空间溢出效应的因果图表示
空间溢出效应可通过空间滞后变量表示:
- X_i通过直接路径影响Y_i
- 通过W*X影响邻近Y_j
- 因果图需包含跨区域关系
局部效应 vs 全局效应
在空间因果图中,可以定义局部因果效应(某区域的因果效应)和全局效应(所有区域的平均效应)。空间杜宾模型中的直接效应和间接效应分解与这种因果图解释相对应。
小组讨论
讨论主题1
在您的研究领域(城市规划/交通/环境GIS),有哪些适合使用因果图方法研究的问题?
- 如何定义处理变量?
- 如何定义结果变量?
讨论主题2
识别您研究中可能存在的混杂因素。
- 如何在因果图中正确处理?
- 哪些因素可能被遗漏?
讨论主题3
因果图方法的局限性是什么?
- 何时应考虑其他方法?
- 工具变量法?倾向得分法?
第三部分
机器学习因果推断方法
机器学习与因果推断的结合
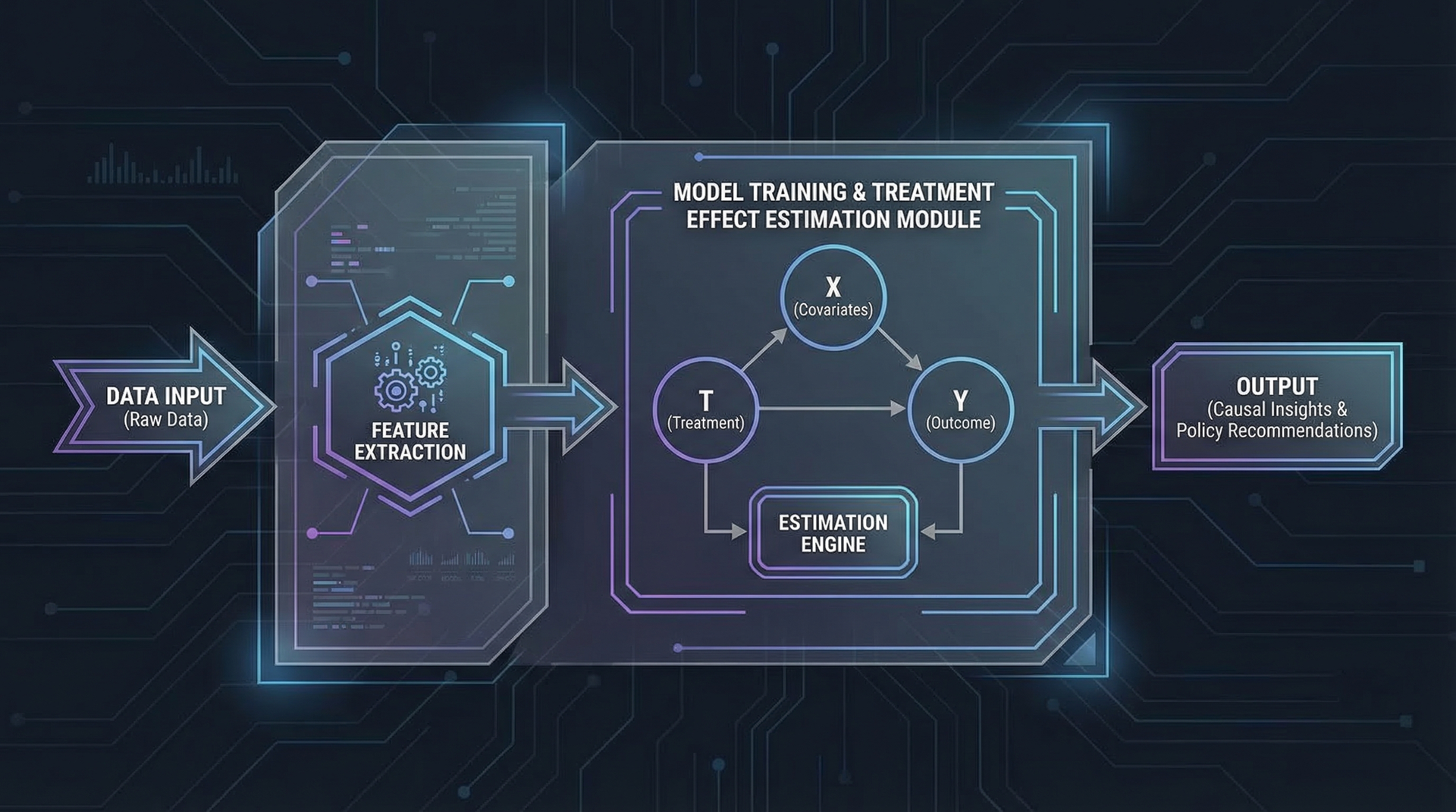
为什么需要机器学习辅助因果推断
- 传统方法依赖线性假设
- 处理高维、非线性数据时存在局限
- 机器学习有强大的函数逼近能力
- 为因果推断提供新工具
双机器学习(DML)
由Chernozhukov等人提出,解决高维混淆变量下的因果效应估计问题。
- 使用ML估计倾向得分和条件期望
- 用残差回归估计因果效应
- 通过交叉拟合控制过拟合
异质处理效应(HTE)
传统ATE假设效应在所有个体中相同,但实际可能因特征而异。
- 因果森林估计个性化效应
- 揭示"谁受益最多"
- 支持精准施策
EconML框架概述
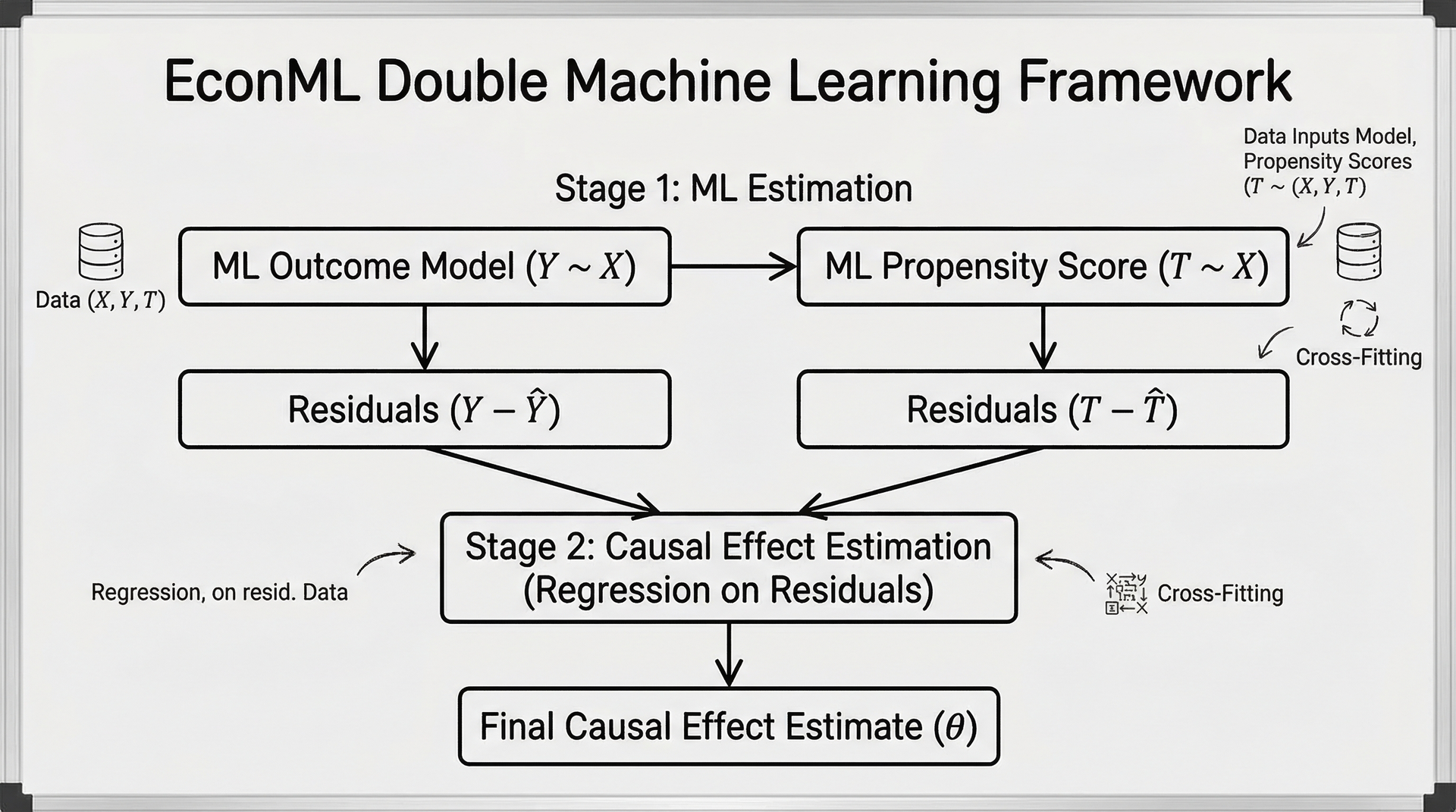
EconML定位与特点
微软开发的Python库,专门用于从观测数据中估计异质处理效应和因果关系。
- 计量经济学 + 机器学习
- 多种高级估计方法
- DoWhy生态系统的核心工具
核心估计方法
- DoubleMachineLearning:通用DML框架
- CausalForestDML:因果森林
- LinearDML:线性DML
- NonParamDML:非参数DML
核心优势
- 统一API接口
- 自动化交叉验证
- 与DoWhy、scikit-learn集成
- 丰富的可视化工具
双机器学习(DML)原理
DML的理论框架
DML用于估计处理变量T对结果变量Y的因果效应,同时控制混淆变量W。
核心步骤:
- 第一阶段:估计E[T|W]和E[Y|W]
- 第二阶段:残差回归
- τ = E[Ỹ/T̃]
残余混杂消除
如果能够精确估计E[T|W]和E[Y|W],则残差项中不包含混淆因素的影响。
- 避免直接建模因果关系
- 残差回归可直接估计效应
- 减少模型依赖性
交叉拟合
使用交叉拟合(Cross-fitting)控制过拟合:
- 将数据分为K折
- 用K-1折训练,剩余1折计算残差
- 轮换确保所有数据参与
- 渐近正态性保证
因果森林与异质处理效应
因果森林的原理
由Athey和Wager提出,将随机森林应用于因果推断。
- 在每个叶子节点内比较处理组和对照组
- 估计局部处理效应
- 集成各节点估计得到整体异质效应
CausalForestDML的实现
结合因果森林和双机器学习:
- 先用DML估计基础效应
- 再用因果森林分析异质性
- 处理高维混淆变量
- 揭示效应异质模式
异质效应的GIS应用
识别哪些区域/人群从政策中获益最多、理解政策效果的差异来源、为精准施策提供依据。例如,识别出哪类城市从交通投资中获益最多。
EconML案例:政策干预区域效果分析
研究背景
研究问题:国家"智慧城市"试点政策对城市经济增长的效果是否因城市特征而异?
数据:
- 中国2012-2020年地级以上城市
- 处理变量:智慧城市试点
- 结果变量:GDP/收入增长率
- 混淆变量:人口、产业结构等
分析结果
使用CausalForestDML估计异质处理效应:
- 高效果城市:信息化基础好
- 高效果城市:人力资本丰富
- 高效果城市:服务业为主
- 空间格局:东部强、中西部弱
EconML代码示例
DML基础代码
from econml.dml import LinearDML
from sklearn.linear_model import LassoCV
# 定义模型
est = LinearDML(
model_y=LassoCV(cv=5), # outcome模型
model_t=LassoCV(cv=5), # treatment模型
discrete_treatment=True,
random_state=42
)
# 拟合模型
est.fit(Y, T, X=W) # Y:outcome, T:treatment, W:controls
# 估计ATE
ate = est.ate(X=W)
print(f"ATE估计: {ate.mean():.4f}")CausalForestDML代码
from econml.dml import CausalForestDML
# 定义因果森林模型
est = CausalForestDML(
n_estimators=100,
max_depth=5,
discrete_treatment=True,
random_state=42
)
# 拟合模型
est.fit(Y, T, X=W)
# 估计异质效应(每个样本的ITE)
hte = est.effect(X)
# 识别高效应样本
high_effect_idx = np.argsort(hte)[-10:]CausalML框架概述
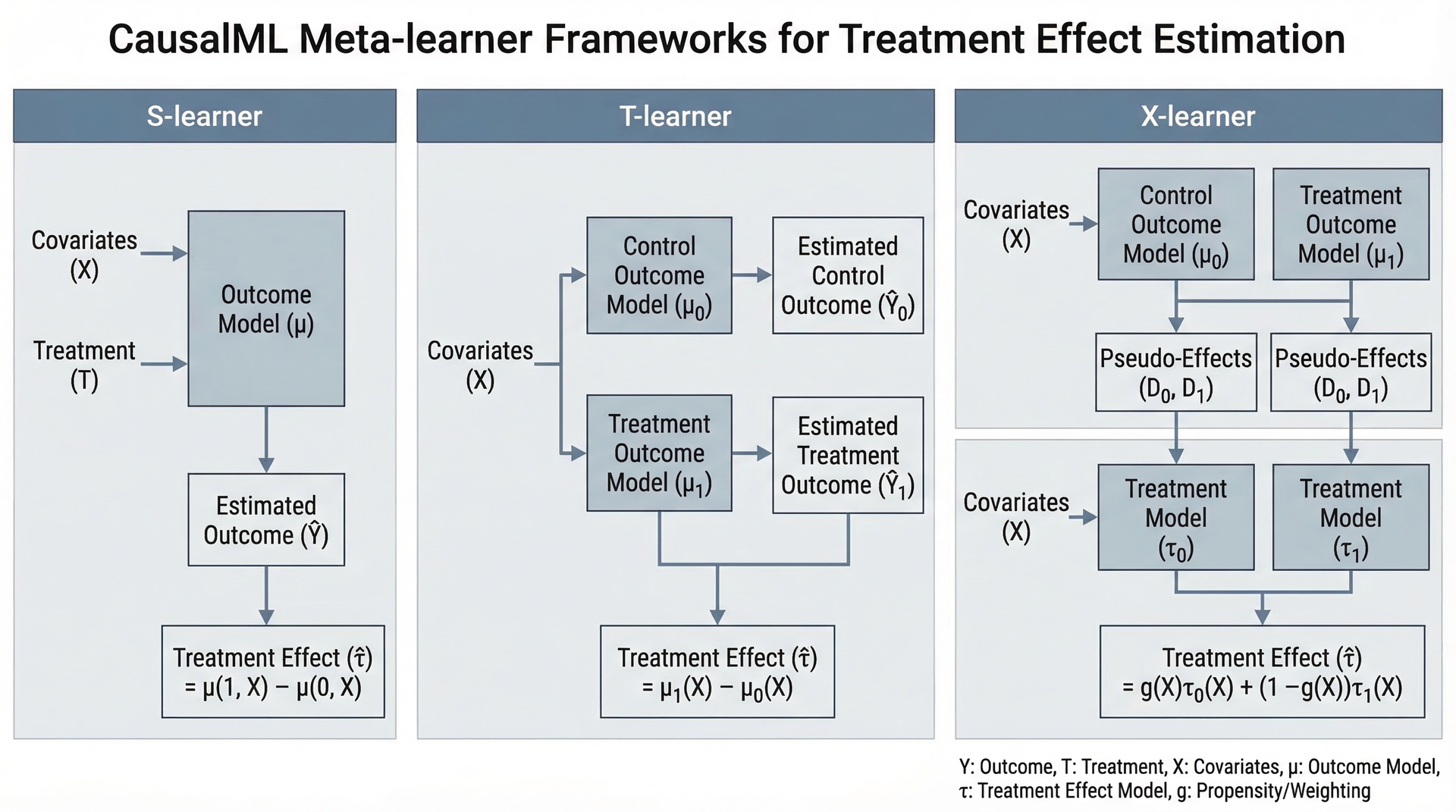
CausalML定位与特点
Uber开发的Python库,专注于使用机器学习方法估计处理效应和uplift建模。
- 元学习者框架(S/T/X-learner)
- Uplift建模
- 丰富的异质效应估计工具
核心方法
- S-learner:单一模型法
- T-learner:两个模型法
- X-learner:交叉模型法
- CausalForest:因果森林
- Uplift Trees:提升树
应用场景
- 客户干预策略优化
- 政策精准推送
- A/B测试异质效应分析
- 资源优化配置
元学习者框架(S/T/X-learner)
S-learner(单一模型法)
将处理变量作为特征之一,建立统一预测模型:
μ(x, t) = E[Y|X, T=t]
处理效应:
τ(x) = μ(x, 1) - μ(x, 0)
- 优点:简单
- 缺点:效应可能被"稀释"
T-learner(两个模型法)
分别建立处理组和对照组模型:
μ₀(x) = E[Y|X, T=0]
μ₁(x) = E[Y|X, T=1]
处理效应:
τ(x) = μ₁(x) - μ₀(x)
- 优点:分别建模更灵活
- 缺点:每个模型只用部分数据
X-learner(交叉模型法)
T-learner的改进,分三步:
- 分别拟合μ₀和μ₁
- 计算虚拟处理效应
- 用虚拟效应拟合效应模型
优势:适合样本不平衡情况
Uplift Modeling原理
Uplift的定义
Uplift(提升度):
τ(x) = E[Y(1) - Y(0)|X=x]
给定特征x条件下,处理相对于不处理的期望增量。
目标:找到uplift最高的群体进行干预
Uplift建模的挑战
每个样本只能观察到Y(1)或Y(0)中的一个,无法直接计算真实uplift。
常用方法:
- 双模型差分法(S/T/X-learner)
- 直接建模法(Class Transformation)
- 树方法(Uplift Trees)
GIS中的应用
在城市规划中,uplift建模可用于:识别最能从基础设施投资中受益的区域、优化公共资源在不同区域的分配、预测干预措施对不同社区的增量效果。
CausalML案例:空间干预策略优化
研究问题
城市公共空间改造项目(口袋公园建设)如何在不同社区产生不同的满意度提升?
决策目标:
在有限财政预算下,选择最具效益的改造点位。
方法与数据
数据:北京市2018-2022年100个社区调查数据
- 是否实施口袋公园改造
- 社区特征(人口、年龄、收入、绿地)
- 居民满意度评分
使用X-learner估计各社区的处理效应。
研究发现与决策建议
高满意度提升社区特征:原有绿地面积较少、老年人口比例较高、周边500米无大型公园。
建议:优先在老城区(绿地稀缺、老龄化程度高)推进口袋公园建设。预算约束下,应聚焦高uplift社区以最大化整体效益。
CausalML代码示例
X-learner代码
from causalml.inference.meta import BaseXClassifier
from sklearn.ensemble import GradientBoostingClassifier
# 定义X-learner
xl = BaseXClassifier(
outcome_learner=GradientBoostingClassifier(),
effect_learner=GradientBoostingClassifier()
)
# 拟合模型
xl.fit(X=df_features,
treatment=df_treatment,
y=df_outcome)
# 估计个体处理效应
ite = xl.predict(X=df_features)Uplift建模代码
from causalml.inference.uplift import BaseTClassifier
# 使用T-learner进行uplift建模
uplift_model = BaseTClassifier(
GradientBoostingClassifier()
)
uplift_model.fit(X=df_features,
treatment=df_treatment,
y=df_outcome)
# 预测uplift分数
uplift_scores = uplift_model.predict(X=df_features)
# 识别高uplift群体
threshold = np.percentile(uplift_scores, 80)
target_population = df_features[uplift_scores >= threshold]机器学习因果推断的GIS应用
适用场景
- 高维空间数据(多尺度遥感特征)
- 建模非线性因果关系
- 识别异质效应
- 大规模数据处理
优势
- 处理复杂数据结构
- 自动选择控制变量
- 揭示非线性效应
- 灵活的模型形式
局限与实践建议
- 解释性挑战(黑箱问题)
- 对数据量和质量要求高
- 重视协变量选择
- 使用交叉验证评估稳健性
方法选择指南
| 研究问题 | 推荐方法 | 工具包 |
|---|---|---|
| 估计平均处理效应(ATE) | 倾向得分/DML | DoWhy + EconML |
| 估计异质处理效应(HTE) | CausalForest | EconML |
| 因果结构发现 | NOTEARS | CausalNex |
| Uplift优化 | 元学习者 | CausalML |
| 时间序列因果 | PCMCI | Tigramite |
综合考量因素
研究目的(探索性 vs 验证性)、结果解释需求(黑箱 vs 白盒)、数据条件(样本量、变量类型)、计算资源。必要时可组合多种方法进行稳健性检验。
第四部分
空间计量经济学方法
空间计量经济学概述
空间计量经济学的起源
由Anselin(1988)系统提出,旨在处理空间数据的依赖性和异质性问题。
核心创新:
- 将空间效应引入计量经济模型
- 空间自相关
- 空间异质性
空间效应的来源
空间依赖性:
- 空间交互(贸易、人口迁移)
- 空间扩散(技术溢出)
- 共同冲击(区域政策)
空间异质性:
- 区域条件差异
- 规模效应
- 边界效应
PySAL生态系统
PySAL(Python Spatial Analysis Library)是空间计量分析的开源生态系统,包含spreg(空间回归)、esda(空间自相关)、libpysal(空间权重)、mgwr(地理加权回归)等模块。
空间权重矩阵构建
空间权重矩阵的定义
空间权重矩阵W是一个n×n矩阵,元素w_ij表示区域i和区域j之间的空间关系。
主要类型:
- 邻接矩阵:共享边界
- 距离矩阵:基于距离衰减
- K近邻矩阵:固定K个邻居
from libpysal.weights import Queen, KNN, DistanceBand
# 邻接矩阵(基于多边形邻接)
w_queen = Queen.from_shapefile('cities.shp')
# K近邻矩阵(每个区域4个最近邻居)
w_knn = KNN.from_shapefile('cities.shp', k=4)
# 距离带矩阵(100km阈值内)
w_dist = DistanceBand.from_shapefile(
'cities.shp', threshold=100
)
# 行标准化
w_knn.transform = 'r'空间滞后模型(SLM)
模型设定
y = ρWy + Xβ + ε
- Wy:因变量的空间滞后
- ρ:空间自相关系数
- β:解释变量系数
解释:本区域因变量如何受到邻近区域因变量的影响。
估计方法
由于空间滞后的存在,需要使用:
- 工具变量法
- 最大似然法(ML)
ML估计:
假设误差项服从空间自相关分布,通过最大化似然函数同时估计所有参数。
空间误差模型(SEM)
模型设定
y = Xβ + u, u = λWu + ε
- u:空间相关误差
- λ:空间误差自相关系数
- ε:独立误差项
估计方法
SEM使用:
- 最大似然法(ML)
- 广义最小二乘法(GLS)
与SLM的区别:
- SLM的ρ显著 → 直接空间溢出效应
- SEM的λ显著 → 空间相关遗漏因素
空间杜宾模型(SDM)
模型设定
y = ρWy + Xβ + WXθ + ε
SDM同时包含因变量和处理变量的空间滞后。
模型关系:
- 约束θ=0 → SLM
- 约束β+θ=0 → SEM
直接效应与间接效应
SDM的重要优势是分解效应:
- 直接效应:本区域X变化对本地Y的影响
- 间接效应:本区域X变化对邻近Y的影响
- 总效应 = 直接 + 间接
这是量化政策溢出效应的关键工具。
PySAL spreg模块详解
spreg模块概述
PySAL中的空间回归模块,提供三类估计方法:
- OLS:普通最小二乘法
- ML:最大似然法
- GM:广义矩估计
支持模型:
SAR、SEM、SAC、SDM、GMM等
from spreg import OLS, ML_Lag, ML_Error
# OLS基准回归
ols = OLS(y, X, w=w_knn,
name_y='GDP',
name_x=['pop','industry'])
# 空间滞后模型ML估计
slag = ML_Lag(y, X, w=w_knn,
name_y='GDP',
name_x=['pop','industry'])
# 空间误差模型ML估计
sem = ML_Error(y, X, w=w_knn,
name_y='GDP',
name_x=['pop','industry'])空间面板数据模型
面板数据空间模型
y_t = ρWy_t + X_tβ + μ_i + λ_t + ε_t
- μ_i:个体固定效应
- λ_t:时间固定效应
- 同时控制空间和时间依赖性
固定效应 vs 随机效应
固定效应模型:
- 个体效应与解释变量相关
- 适合样本为总体
随机效应模型:
- 个体效应与解释变量无关
- 适合随机样本
Hausman检验可帮助选择。
空间计量经济学案例:区域经济增长
研究背景
研究问题:FDI对区域经济增长的影响是否存在空间溢出效应?
- FDI是否通过集聚效应影响邻近区域
- 是否存在竞争效应
数据与模型
数据:中国2000-2020年省级面板
- GDP增长率(结果)
- FDI占GDP比重(处理)
- 人力资本、基础设施、制度环境
模型:SDM with fixed effects
研究结果
FDI对本地经济增长的直接效应显著为正。FDI对邻近区域的间接效应也显著为正,说明存在正向技术溢出。总效应表明FDI每增加1%,区域GDP增长约0.3%。
PySAL代码示例
完整SDM分析
from spreg import ML_Lag
import geopandas as gpd
from libpysal.weights import Queen
# 加载数据
gdf = gpd.read_file('provinces.shp')
# 构建空间权重矩阵
w = Queen.from_dataframe(gdf)
w.transform = 'r'
# 准备变量
y = gdf['GDP_growth'].values
X = gdf[['FDI', 'human_capital',
'infrastructure']].values
# 估计SDM
sdm = ML_Lag(y, X, w=w,
name_y='GDP_growth',
name_x=['FDI', 'human_capital',
'infrastructure'],
name_ds='Province Data')
print(sdm.summary)效应分解
from scipy.linalg import inv
import numpy as np
# 提取参数
beta = sdm.betas
rho = sdm.rho
theta = sdm.theta
# 逆矩阵计算
W = w.full()[0]
I = np.eye(len(W))
inv_term = inv(I - rho * W)
# 简化效应分解
direct_effect = beta.mean()
indirect_effect = (rho * W).sum() / len(W)
print(f"直接效应: {direct_effect:.4f}")
print(f"间接效应: {indirect_effect:.4f}")空间溢出效应分解
偏微分解释框架
LeSage和Pace(2009)提出偏微分方法:
∂y/∂x_j = (I - ρW)⁻¹(β_j I + θ_j W)
分解:
- 对角线元素均值 = 直接效应
- 非对角线元素均值 = 间接效应
GIS解释与应用
直接效应:
- 本区域X变化通过自身渠道影响Y
- 包含反馈循环(邻居→本地→邻居)
间接效应:
- 本区域X变化通过空间渠道影响邻居Y
- 量化空间外部性
对政策制定至关重要——本地政策对邻近区域的溢出不容忽视。
MGWR多尺度地理加权回归
MGWR的提出动机
传统GWR假设所有变量的空间尺度相同(共享带宽),但实际上:
- 人口密度的影响可能是局部的(街道尺度)
- GDP的影响可能是区域尺度的
MGWR允许每个回归系数有不同的空间尺度。
MGWR的模型设定
y_i = Σ_j X_ij β_bw_j(u_i, v_i) + ε_i
其中bw_j是变量j的带宽参数:
- 带宽大 → 影响越全局
- 带宽小 → 影响越局部
MGWR与GWR的区别
GWR:单一尺度
- 所有变量使用相同带宽
- 隐含假设所有变量在同一尺度发挥作用
MGWR:多尺度
- 每个变量有独立带宽
- 允许不同变量在不同尺度发挥作用
GWR适用场景
- 假设所有变量局部效应
- 效应随距离平滑变化
MGWR适用场景
- 变量混合局部和全局效应
- 不同变量有不同空间结构
- 带宽差异本身有解释价值
MGWR案例:城市房价影响因素分析
研究问题
城市房价受哪些因素影响?这些因素的影响是否存在空间异质性?不同因素的影响是否在不同的空间尺度上发挥作用?
数据与方法
数据:北京市2020年1km网格房价
- 地铁站密度
- 学校密度
- 医院密度
- 绿地覆盖率
- 商服中心距离
研究发现
地铁站密度呈现多尺度特征:市中心区域(局部尺度)地铁影响弱(已有密集交通),郊区(区域尺度)地铁影响强。绿地覆盖率在全市尺度上影响一致。商服中心距离在街道尺度上影响差异大。
MGWR代码示例
MGWR分析代码
from mgwr.gwr import MGWR
from mgwr.sel_bw import Sel_BW
import geopandas as gpd
import numpy as np
# 准备数据
gdf = gpd.read_file('beijing_housing.shp')
coords = np.array(list(zip(
gdf.geometry.centroid.x,
gdf.geometry.centroid.y
)))
y = gdf['price'].values.reshape(-1, 1)
X = gdf[['metro', 'school', 'hospital',
'green', 'distance']].values
# 带宽选择与MGWR拟合
selector = Sel_BW(coords, y, X, multi=True)
bw = selector.search(multi_bw_min=[2],
multi_bw_max=[100])
mgwr_model = MGWR(coords, y, X, selector, multi=True)
results = mgwr_model.fit()结果解读与可视化
# 各变量的带宽(尺度参数)
print("Variable Bandwidths:", results.BW)
# 带宽含义:带宽越大,影响越全局
# 局部R²
print("Local R²:", results.R2)
# 系数空间分布
for i, var in enumerate(['metro','school',
'hospital','green','dist']):
gdf[var + '_coef'] = results.params[:, i]
gdf.plot(var + '_coef', cmap='RdBu_r',
legend=True, figsize=(8,6))空间计量方法的GIS应用总结
方法选择框架
- 空间依赖 → SLM/SEM/SDM
- 分解溢出 → SDM
- 空间异质 → GWR/MGWR
- 面板+空间 → FE Spatial Panel
因果推断视角
空间计量模型本质上是描述性的,但可与因果推断结合:
- SDM间接效应分解
- 量化"政策→邻居结果"
- 工具变量+空间模型
实践建议
- 空间自相关诊断(Moran's I)
- LM检验选择模型
- 效应分解量化溢出
- GWR/MGWR探索异质
- 多种方法稳健性检验
第五部分
时间序列与贝叶斯方法
时间序列因果发现概述
时间序列因果推断的意义
许多GIS问题涉及时间维度:
- 气候变化的因果链条
- 疾病传播的时间动态
- 经济发展的时间滞后效应
- 环境扩散过程
因果发现的挑战
- 高维变量组合(时间滞后增加维度)
- 虚假因果(相关但非因果)
- 非线性因果关系
- 混淆因素控制
- 多重假设检验
主要方法分类
- 格兰杰因果检验:基于预测能力
- 条件独立性检验:PC算法时间扩展
- 信息论方法:Transfer Entropy
- 结构学习方法:PCMCI
Tigramite框架与PCMCI算法
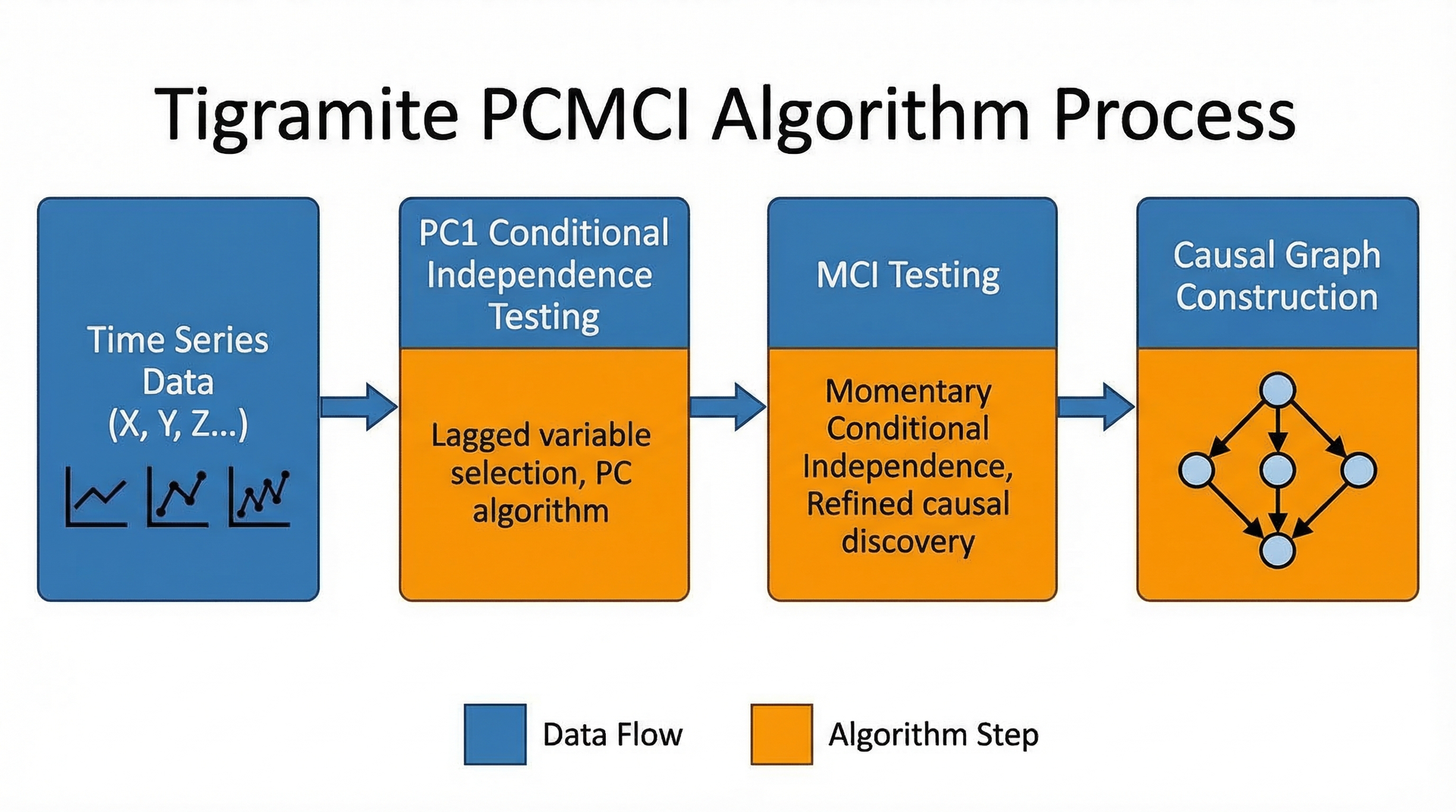
Tigramite概述
时间序列因果发现的专业Python库,实现PCMCI算法。
核心功能:
- 从时间序列中发现因果关系
- 输出因果图和时间滞后强度
- 处理未观测混杂
PCMCI算法原理
PCMCI分为两步:
- PC1:逐步去除冗余父节点
- MCI:检验剩余父节点的因果显著性
在高维情况下比完整条件独立测试更有效率。
核心参数
- tau_max:最大时间滞后
- alpha:显著性水平
- pc_alpha:PC1阈值
- link_matrix:可能的因果链路
Tigramite因果推断流程
1. 数据预处理
标准化时间序列
2. 定义测试
选择条件独立测试
3. PCMCI分析
运行因果发现
4. 结果解释
可视化因果图
from tigramite.pcmci import PCMCI
from tigramite.independence_tests import ParCorr
# PCMCI分析
pcmci = PCMCI(dataframe=data, cond_ind_test=ParCorr())
results = pcmci.run_pcmci(tau_max=5, pc_alpha=0.05)
# 显著因果链路
print(results['p_matrix']) # p值矩阵
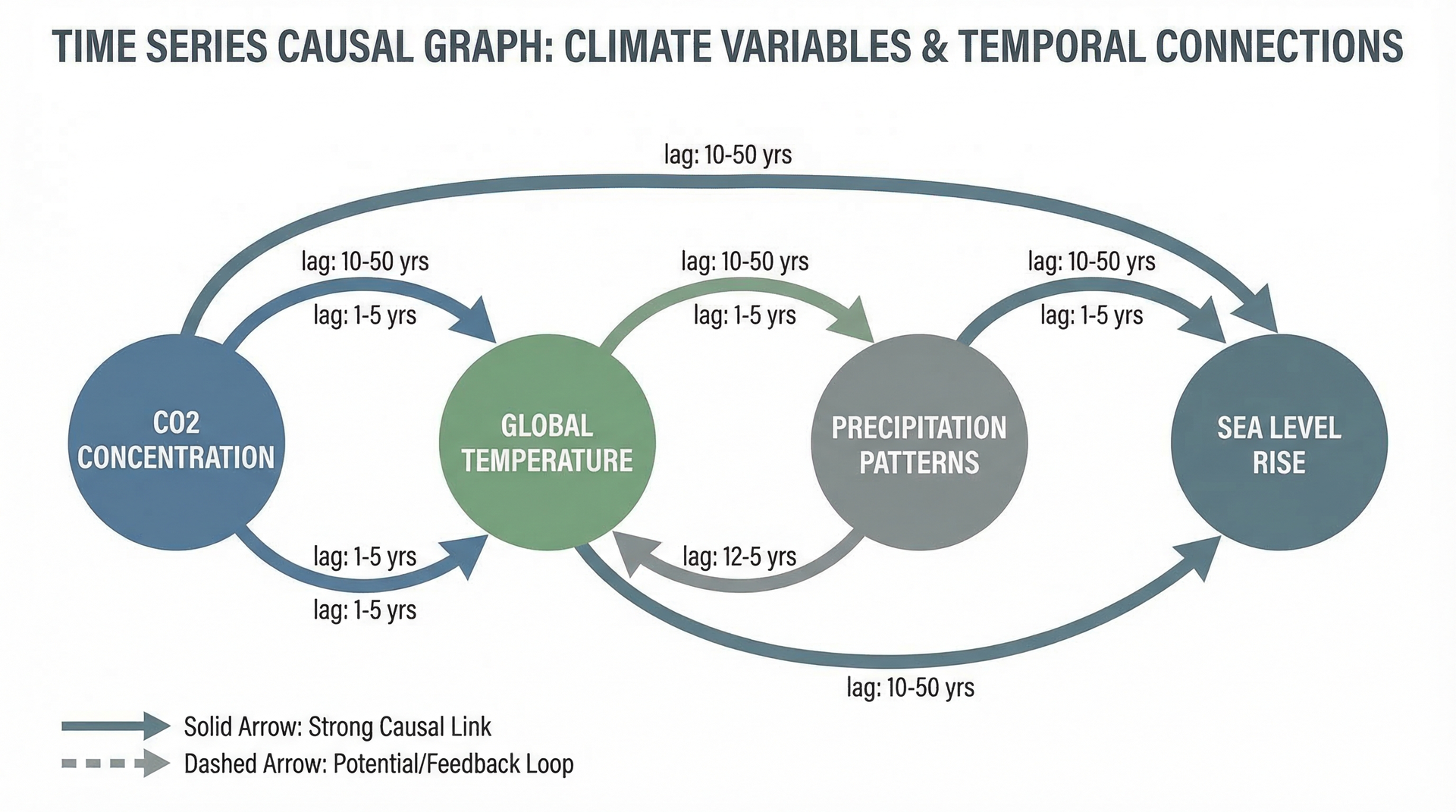
print(results['val_matrix']) # 因果强度Tigramite案例:气候变化因果分析
研究问题
研究CO2排放、气温、降水、海平面等气候变量之间的因果关系,理解气候变化的驱动机制和反馈回路。
数据
数据:中国1960-2020年年度气候数据
- CO2浓度
- 全球平均气温距平
- 年降水量
- 海平面高度
- 植被覆盖指数(NDVI)
因果发现结果
主要因果链路:
- CO2↑ → 气温↑(直接因果,滞后0-2年)
- 气温↑ → 海平面↑(热膨胀+冰融)
- CO2↑ → 植被覆盖↓(通过气温和降水)
- 气温↑ → 降水量变化(非线性影响)
结果支持了CO2是全球变暖主因的科学共识。
Tigramite代码示例
完整分析代码
import tigramite.data_processing as pp
from tigramite.pcmci import PCMCI
from tigramite.independence_tests import ParCorr
import pandas as pd
# 加载数据
df = pd.read_csv('climate_data.csv', index_col=0)
var_names = ['CO2', 'Temp', 'Precip', 'SeaLevel', 'NDVI']
data = pp.DataFrame(df.values,
datatime=np.arange(len(df)),
var_names=var_names)
# PCMCI分析
parcorr = ParCorr(significance='analytic')
pcmci = PCMCI(dataframe=data, cond_ind_test=parcorr)
results = pcmci.run_pcmci(tau_max=5, pc_alpha=0.05)可视化代码
from tigramite.plotting import plot_time_series_graph
# 因果图可视化
plot_time_series_graph(
val_matrix=results['val_matrix'],
sig_mask=results['sig_matrix'],
var_names=var_names,
link_matrix=results['link_matrix'],
figsize=(10, 6)
)
plt.savefig('causal_graph.png')敏感性分析:测试不同alpha和tau_max参数下的结果稳健性
PyMC贝叶斯概率编程

PyMC概述
Python中的贝叶斯概率编程库,使用马尔可夫链蒙特卡洛(MCMC)进行贝叶斯推断。
核心能力:
- 定义自定义概率模型
- 从后验分布采样
- 支持复杂层次模型
贝叶斯推断优势
- 自然处理不确定性(完整后验分布)
- 支持层次模型(共享信息)
- 易于加入先验知识
- 模型复杂度可灵活增加
PyMC在GIS中的应用
- 空间层级模型(城市→区县→社区)
- 空间过程建模(高斯过程)
- 疾病制图(空间相依的疾病率)
- 贝叶斯网络(概率推断)
PyMC空间贝叶斯模型
空间层级模型
import pymc3 as pm
with pm.Model() as model:
# 超先验
sigma_region = pm.HalfNormal('sigma_region', sigma=1)
# 区域效应
region_effect = pm.Normal('region_effect',
mu=0, sigma=sigma_region,
shape=n_regions)
# 固定效应
beta = pm.Normal('beta', mu=0, sigma=10)
# 线性预测
mu = beta * X + region_effect[region_idx]
# 似然
y_obs = pm.Normal('y_obs', mu=mu,
sigma=sigma_obs, observed=y)CAR空间先验
with pm.Model() as spatial_model:
# CAR先验
tau_spatial = pm.HalfNormal('tau_spatial', sigma=1)
spatial_effect = pm.distributions.CAR(
'spatial_effect',
mu=0, tau=tau_spatial,
W=adjacency_matrix
)
# 其余代码同上
# 模型拟合
with spatial_model:
trace = pm.sample(2000, tune=1000, cores=2)PyMC案例:空间疾病制图
研究问题
研究空气污染(PM2.5)对呼吸道疾病发病率的空间影响,同时考虑社会经济和医疗资源因素。
目标:
- 估计每个区县的风险系数
- 识别高风险区域
数据
数据:中国2019年区县级数据
- 呼吸道疾病发病率(SIR)
- PM2.5年均浓度
- 人口密度
- 医疗机构密度
- 人均收入
使用邻接矩阵表示空间结构。
模型与结果
使用泊松似然建模疾病计数,包含CAR空间先验。结果显示PM2.5效应存在空间异质性,北方工业区效应更强。
贝叶斯因果推断的未来方向
深度学习 + 贝叶斯
- 变分自编码器用于因果发现
- 贝叶斯神经网络量化不确定性
- 因果表示学习
因果发现与推断统一
- 从数据中学习因果结构
- 在已知结构下估计效应
- AutoML for Causal Inference
GIS整合前沿
- 时空贝叶斯层次模型
- 空间因果发现
- 基于GIS的因果实验设计
第五部分小结
核心要点
- Tigramite:时间序列因果发现,PCMCI高效可靠
- PyMC:灵活的贝叶斯概率编程
- 时间序列方法揭示因果时滞结构
- 贝叶斯方法自然处理不确定性
实践建议
- 结合GIS数据进行时空因果分析
- 使用PyMC构建空间层次模型
- 关注贝叶斯与深度学习的融合
- 探索因果推断的自动化流程
第六部分
总结与展望
各方法对比与适用场景
因果图方法
DoWhy、CausalNex:适合有明确因果假设的验证性研究
机器学习方法
EconML、CausalML:适合高维数据下的异质效应估计
空间计量方法
PySAL、MGWR:适合分析空间依赖和溢出效应
时间序列与贝叶斯
Tigramite、PyMC:适合时间因果链条和不确定性分析
方法选择指南
| 研究问题 | 推荐方法 | 推荐工具 |
|---|---|---|
| 探索因果假设 | 因果发现 | CausalNex |
| 验证因果假设 | 因果图 + 反驳测试 | DoWhy |
| 估计政策效应 | DML | EconML |
| 发现谁受益最多 | 因果森林 | CausalML |
| 分析空间溢出 | SDM | PySAL |
| 多尺度空间效应 | MGWR | PySAL mgwr |
| 时间因果链条 | PCMCI | Tigramite |
| 处理不确定性 | 贝叶斯推断 | PyMC |
GIS因果推断最佳实践
研究设计原则
- 明确因果问题
- 利用随机分配(实验最优)
- 选择合适对照
- 控制关键混杂
- 考虑时间维度
数据处理要点
- 空间数据对齐
- 处理缺失值
- 检验空间自相关
- 考虑数据聚合层次
- 注意生态学谬误
结果报告标准
- 报告完整模型规范
- 报告点估计和不确定性
- 报告稳健性检验
- 讨论因果假设合理性
开源工具生态系统
Python因果推断生态
- DoWhy + EconML:微软因果推理生态
- CausalNex:Uber因果发现与推断
- CausalML:Uber异质效应估计
- PySAL:空间分析生态
- Tigramite:时间序列因果
- PyMC:贝叶斯建模
GIS软件集成
- Python + GeoPandas/Rasterio:空间数据处理
- ArcGIS/QGIS:空间可视化和地图制作
- Jupyter Notebook:交互式分析环境
- Docker:环境复现

未来研究方向
方法前沿
- 因果表示学习
- 因果迁移学习
- 动态因果发现
- 因果公平性分析
GIS应用前沿
- 时空因果推断
- 空间政策实验
- 数字孪生因果模拟
- 人地系统耦合建模
技术整合前沿
- 大语言模型辅助因果推断
- 因果验证自动化流程
- 可解释AI与因果推断结合
- 实时因果监测预警
参考资源与学习路径
经典教材
- Pearl:《Causality: Models, Reasoning, and Inference》
- Imbens & Rubin:《Causal Inference for the Social Sciences》
- Anselin & Rey:《Handbook of Spatial Analysis》
- Lesage & Pace:《Spatial Econometrics》
在线资源
- DoWhy:microsoft.github.io/dowhy
- CausalNex:causalnex.readthedocs.io
- EconML:www.econml.org
- PySAL:pysal.org
- Tigramite:jakobrunge.com/tigramite
学习路径建议
入门:DoWhy基础 + 空间计量基础 → 进阶:因果发现 + 机器学习因果推断 → 高级:时空因果 + 贝叶斯层次模型 → 持续:最新论文和工具更新
